
본 논문은 ECCV 2020에 투고된 3D Scene Reconstruction 분야 논문 중 높은 성능을 보인 논문이다.
1. Introduction
컴퓨터 비전 분야에서 우리 주변 세계를 재구성하는 것은 오래된 목표이다. AR, 자율주행과 같은 많은 응용 프로그램이 등장하고, 이는 3D 재구성에 크게 의존한다. 이 재구성은 구조화된 빛, ToF, LIDAR 등과 같은 특수한 센서들을 활용하여 깊이를 측정하고, 이를 3D Model로 융합한다. 이는 효과적이지만 , 가격이 비싸고, 특수한 하드웨어가 필요하다.
다른 방법론으로는 단안영상, MVS, Stereo Method 등 RGB 카메라를 사용하여 깊이 지도를 예측한다. 이는 위의 센서들 보다 덜 정확하고, 만족스럽지 못한다고 저자는 설명한다.
본 논문에서 저자는 Sequnce RGB Image를 가지고, 3D Model을 예측하는 End-to-End Network을 제안한다. 이를 통해 네트워크는 더 많은 정보를 융합하고, 3D Geometric 사전 정보를 학습하여, 더 나은 재구성을 생성한다. 또한, 키프레임을 선택함으로써, 시스템의 복잡성을 줄이고 코스트를 줄인다.
본 논문의 방법은 Cost volume based MVS(Multi View Stereo), TSDF(Truncated Signed Distance Function) Fusion 방법을 사용한다.
먼저, RGB Image에서 2D CNN을 통해 Features를 추출하고 이를 Back Project을 통해 3D Feature Volume을 생성한다. 이를 3D CNN을 통해 TSDF Volume으로 재생성한다.
2. Method
Input : length sequnece of RGB Image with intrinsics and pose
아래는 전체 네트워크 구성이다.
2.1 Feautre Volume Construction
먼저 입력인 시퀀스 이미지를 Backbone Netwokr (2D CNN) 을 통과시켜, 2D Feature를 추출한다. 이후 보유하고 있는 Camera Parameters, Pose와 2D Feature와 수식(1)을 활용하여 World Space의 Voxle 좌표를 구하는 Back Projection을 진행한다. 이를 통해 3D Voxel Volume을 얻을 수 있다. 이러한 Volume은 모든 Sequnce에서 TSDF Fusion과 유사하게 Weighted Average-수식 (2)을 통해 축적되어 하나의 Volume을 얻을 수 있다.
2.2 3D Encoder-Decoder
위에서 축적된 하나의 Volume을 입력으로 한다. AutoEncoder 구조를 활용하여 3D Enoder-Deconder Network를 구성했다. 이를 통해 Feature을 Refine 하고, TSDF Output을 추출한다.
위 그림처럼 Encoder-Decoder는 residual blocks, Downsampling, Upsampling으로 구성되고 각각은 위와 같다.
또한 마지막 레이어에 1x1x1 CNN을 사용하여 TSDF Value를 추출한다. Sematic Segmentation Model 또한, 1x1x1 CNN을 통해 Segmentation Logits을 예측한다.
3. Implemenation Deatils
해당 부분은 논문에서 따로 살펴보는게 구현 및 이해하기에는 편하다. 하지만 장면의 개수는 짚고 넘어가야 할 것 같다.
본 논문 다음에 나온 NeuraRecon과 다르게, 본 논문은 전체 시퀀스에서 50개의 이미지를 랜덤으로 선택하여 입력으로 사용한다. 해당 부분은 다른 논문들과 많이 다르다. 논문에서는 Backbone Netwokr와 Encoder-Decoder 구성 방법 및 사용한 Loss와 Optimizer 등 다양한 Parameters를 설명하고 있다. 만약 구현을 원한다면 논문과 github를 참고하는 것이 좋을 것 같다.
3. Results
본 논문은 ScanNet을 활용하여 평가를 진행하였다. 평가 지표는 아래의 표와 같다
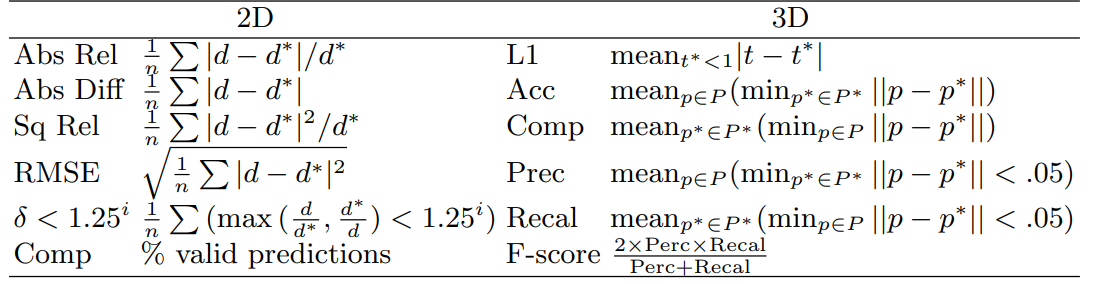
나는 3D 재구성을 목적을 두고 해당 논문을 읽고 공부 했기 때문에 3D geometry Metrics에 대해서만 결과를 확인하였다. 본 논문은 컴퓨터 비전 기반의 방법론인 COLMAP, Depth 기반의 방법론들을 비교하였다. 결과는 아래와 같다.
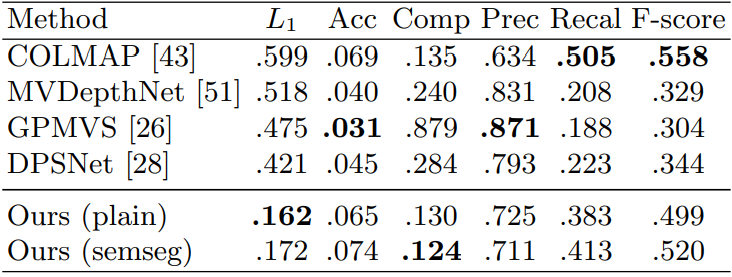
이전의 방법론들 보다 L1 Score에서 많은 차이를 보여주고 있다.

본 논문은 기존의 다른 방법과 다르게 Depth Map을 사용하지 않고, End-to-End로 3D Model을 구성할 수 있다. 다음은 본 논문의 성능을 뛰어넘은 NeuralReocon을 포스팅할 예정이다.
출처
Project Page : http://zak.murez.com/atlas/
github : https://github.com/magicleap/Atlas

